对动态规划发动降维打击


![]()
![]()

通知:数据结构精品课 和 递归算法专题课 限时附赠网站会员,全新纸质书《labuladong 的算法笔记》 出版,签名版限时半价!另外,建议你在我的 网站 学习文章,体验更好。
{kind=link}
-----------
写在最前面:状态压缩并不难,可以理解为一种投机取巧的办法去优化某些动态规划问题的空间复杂度。我个人认为状态压缩并不是必须掌握的技巧,如果你对这个技巧感兴趣,务必阅读并理解 动态规划系列答疑篇。
我们号之前写过十几篇动态规划文章,可以说动态规划技巧对于算法效率的提升非常可观,一般来说都能把指数级和阶乘级时间复杂度的算法优化成 O(N^2),堪称算法界的二向箔,把各路魑魅魍魉统统打成二次元。
但是,动态规划求解的过程中也是可以进行阶段性优化的,如果你认真观察某些动态规划问题的状态转移方程,就能够把它们解法的空间复杂度进一步降低,由 O(N^2) 降低到 O(N)。
note:之前我在本文中误用了「状态压缩」这个词,有读者指出「状态压缩」这个词的含义是把多个状态通过二进制运算用一个整数表示出来,从而减少
dp数组的维度。而本文描述的优化方式是通过观察状态转移方程的依赖关系,从而减少dp数组的维度,确实和「状态压缩」有所区别。所以严谨起见,我把原来文章中的「状态压缩」都改为了「空间压缩」,避免名词的误用。
能够使用空间压缩技巧的动态规划都是二维 dp 问题,你看它的状态转移方程,如果计算状态 dp[i][j] 需要的都是 dp[i][j] 相邻的状态,那么就可以使用空间压缩技巧,将二维的 dp 数组转化成一维,将空间复杂度从 O(N^2) 降低到 O(N)。
什么叫「和 dp[i][j] 相邻的状态」呢,比如前文 最长回文子序列 中,最终的代码如下:
int longestPalindromeSubseq(String s) {
int n = s.length();
// dp 数组全部初始化为 0
int[][] dp = new int[n][n];
// base case
for (int i = 0; i < n; i++) {
dp[i][i] = 1;
}
// 反着遍历保证正确的状态转移
for (int i = n - 1; i >= 0; i--) {
for (int j = i + 1; j < n; j++) {
// 状态转移方程
if (s.charAt(i) == s.charAt(j)) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = Math.max(dp[i + 1][j], dp[i][j - 1]);
}
}
}
// 整个 s 的最长回文子串长度
return dp[0][n - 1];
}tip:我们本文不探讨如何推状态转移方程,只探讨对二维 DP 问题进行空间压缩的技巧。技巧都是通用的,所以如果你没看过前文,不明白这段代码的逻辑也无妨,完全不会阻碍你学会空间压缩。
你看我们对 dp[i][j] 的更新,其实只依赖于 dp[i+1][j-1], dp[i][j-1], dp[i+1][j] 这三个状态:
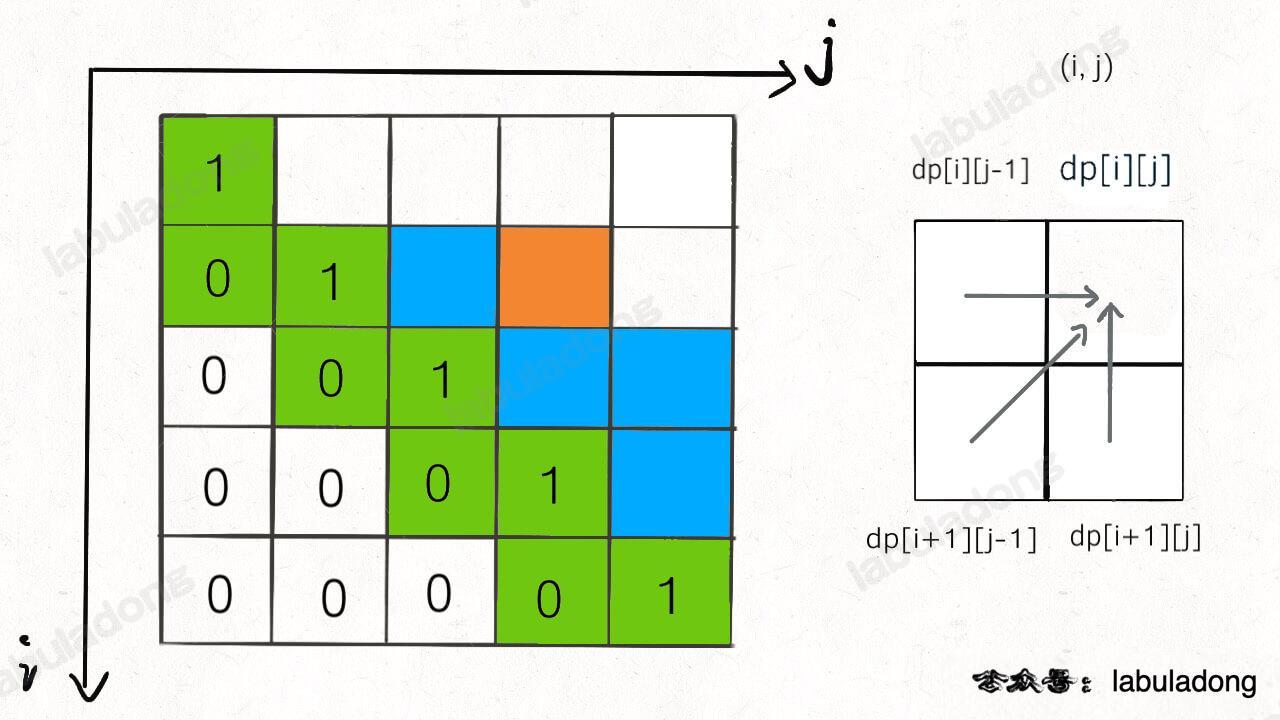
这就叫和 dp[i][j] 相邻,反正你计算 dp[i][j] 只需要这三个相邻状态,其实根本不需要那么大一个二维的 dp table 对不对?空间压缩的核心思路就是,将二维数组「投影」到一维数组:
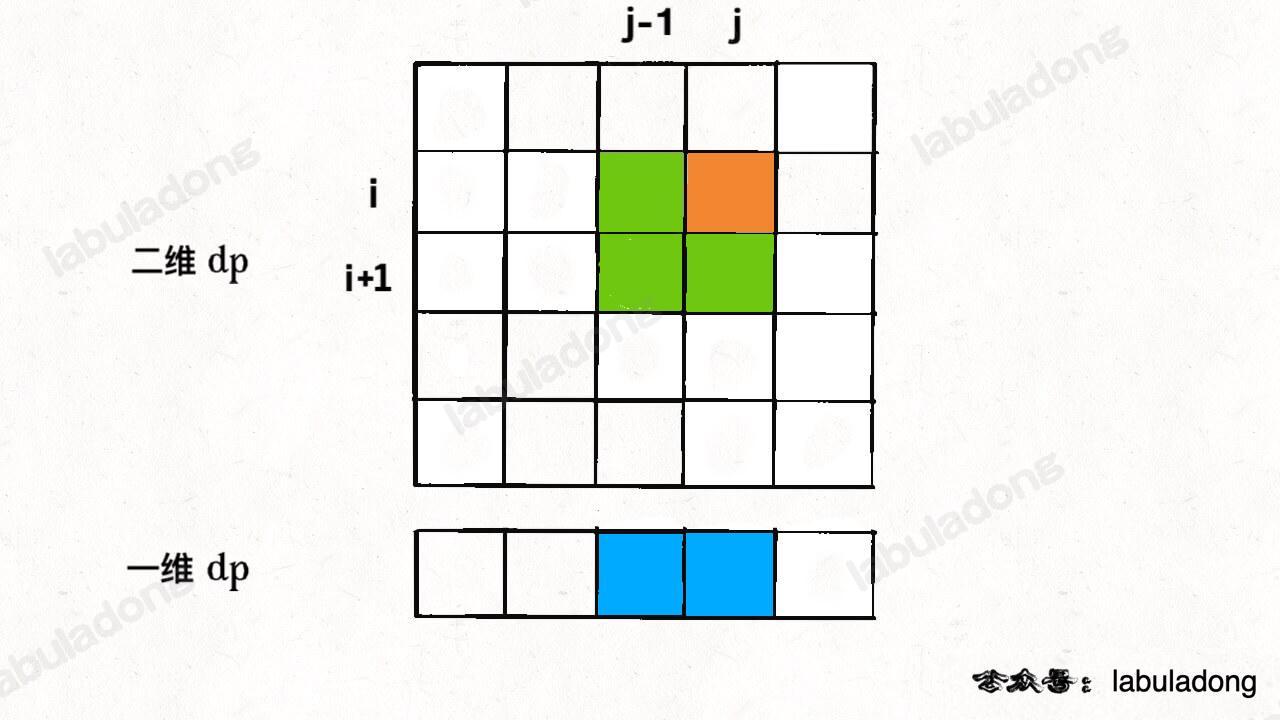
「投影」这个词应该比较形象吧,说白了就是希望让一维数组发挥原来二维数组的作用。
思路很直观,但是也有一个明显的问题,图中 dp[i][j-1] 和 dp[i+1][j-1] 这两个状态处在同一列,而一维数组中只能容下一个,那么他俩投影到一维必然有一个会被另一个覆盖掉,我还怎么计算 dp[i][j] 呢?
这就是空间压缩的难点,下面就来分析解决这个问题,还是拿「最长回文子序列」问题举例,它的状态转移方程主要逻辑就是如下这段代码:
for (int i = n - 2; i >= 0; i--) {
for (int j = i + 1; j < n; j++) {
// 状态转移方程
if (s[i] == s[j])
dp[i][j] = dp[i + 1][j - 1] + 2;
else
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
}回想上面的图,「投影」其实就是把多行变成一行,所以想把二维 dp 数组压缩成一维,一般来说是把第一个维度,也就是 i 这个维度去掉,只剩下 j 这个维度。压缩后的一维 dp 数组就是之前二维 dp 数组的 dp[i][..] 那一行。
我们先将上述代码进行改造,直接无脑去掉 i 这个维度,把 dp 数组变成一维:
for (int i = n - 2; i >= 0; i--) {
for (int j = i + 1; j < n; j++) {
// 在这里,一维 dp 数组中的数是什么?
if (s[i] == s[j])
dp[j] = dp[j - 1] + 2;
else
dp[j] = Math.max(dp[j], dp[j - 1]);
}
}上述代码的一维 dp 数组只能表示二维 dp 数组的一行 dp[i][..],那我怎么才能得到 dp[i+1][j-1], dp[i][j-1], dp[i+1][j] 这几个必要的的值,进行状态转移呢?
在代码中注释的位置,将要进行状态转移,更新 dp[j],那么我们要来思考两个问题:
1、在对 dp[j] 赋新值之前,dp[j] 对应着二维 dp 数组中的什么位置?
2、dp[j-1] 对应着二维 dp 数组中的什么位置?
对于问题 1,在对 dp[j] 赋新值之前,dp[j] 的值就是外层 for 循环上一次迭代算出来的值,也就是对应二维 dp 数组中 dp[i+1][j] 的位置。
对于问题 2,dp[j-1] 的值就是内层 for 循环上一次迭代算出来的值,也就是对应二维 dp 数组中 dp[i][j-1] 的位置。
那么问题已经解决了一大半了,只剩下二维 dp 数组中的 dp[i+1][j-1] 这个状态我们不能直接从一维 dp 数组中得到:
for (int i = n - 2; i >= 0; i--) {
for (int j = i + 1; j < n; j++) {
if (s[i] == s[j])
// dp[i][j] = dp[i+1][j-1] + 2;
dp[j] = ?? + 2;
else
// dp[i][j] = max(dp[i+1][j], dp[i][j-1]);
dp[j] = Math.max(dp[j], dp[j - 1]);
}
}因为 for 循环遍历 i 和 j 的顺序为从左向右,从下向上,所以可以发现,在更新一维 dp 数组的时候,dp[i+1][j-1] 会被 dp[i][j-1] 覆盖掉,图中标出了这四个位置被遍历到的次序:
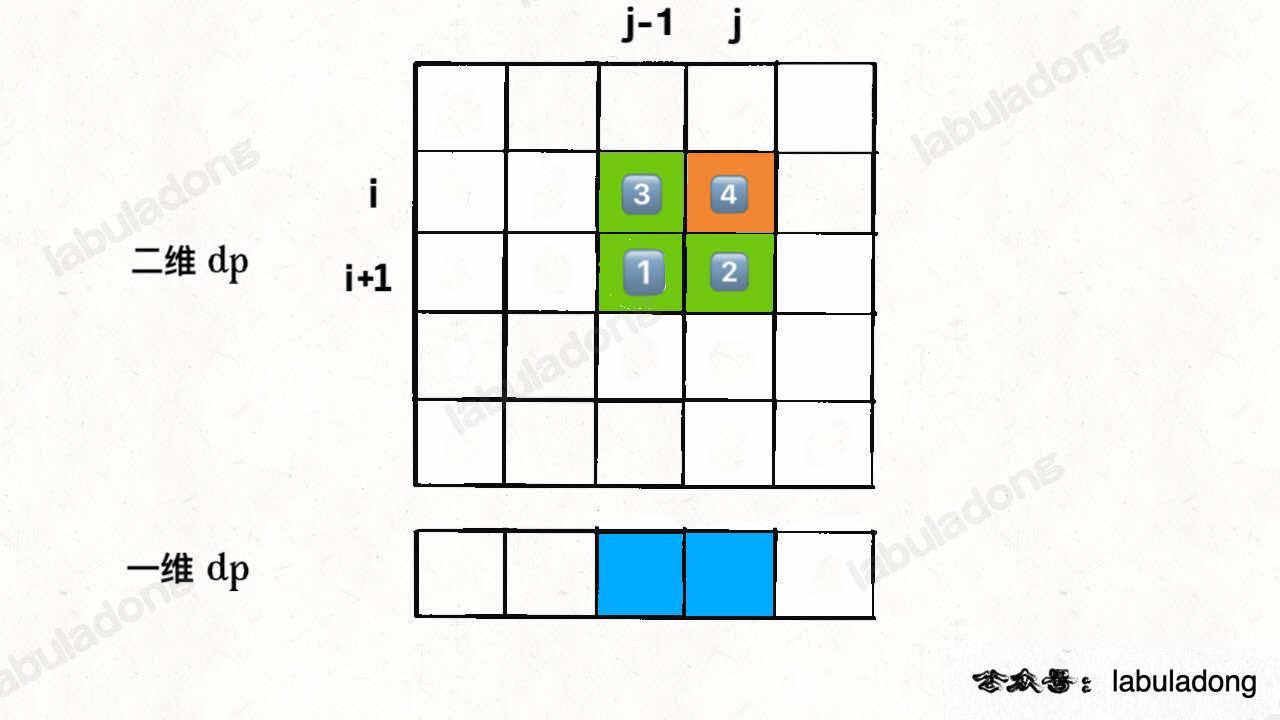
那么如果我们想得到 dp[i+1][j-1],就必须在它被覆盖之前用一个临时变量 temp 把它存起来,并把这个变量的值保留到计算 dp[i][j] 的时候。为了达到这个目的,结合上图,我们可以这样写代码:
for (int i = n - 2; i >= 0; i--) {
// 存储 dp[i+1][j-1] 的变量
int pre = 0;
for (int j = i + 1; j < n; j++) {
int temp = dp[j];
if (s[i] == s[j])
// dp[i][j] = dp[i+1][j-1] + 2;
dp[j] = pre + 2;
else
dp[j] = Math.max(dp[j], dp[j - 1]);
// 到下一轮循环,pre 就是 dp[i+1][j-1] 了
pre = temp;
}
}别小看这段代码,这是一维 dp 最精妙的地方,会者不难,难者不会。为了清晰起见,我用具体的数值来拆解这个逻辑:
假设现在 i = 5, j = 7 且 s[5] == s[7],那么现在会进入下面这个逻辑对吧:
for (int i = 5; i--) {
for (int j = 7; j++) {
if (s[5] == s[7])
// dp[5][7] = dp[i+1][j-1] + 2;
dp[7] = pre + 2;
}
}我问你这个 pre 变量是什么?是内层 for 循环上一次迭代的 temp 值。
那我再问你内层 for 循环上一次迭代的 temp 值是什么?是 dp[j-1] 也就是 dp[6],但请注意,这是外层 for 循环上一次迭代对应的 dp[6],不是现在的 dp[6]。
这个要对应二维数组的索引来理解。你现在的 dp[6] 是二维 dp 数组中的 dp[i][6] = dp[5][6],而人家这个 temp 是二维 dp 数组中的 dp[i+1][6] = dp[6][6]。
也就是说,pre 变量就是 dp[i+1][j-1] = dp[6][6],也就是我们想要的结果。
那么现在我们成功对状态转移方程进行了降维打击,算是最硬的的骨头啃掉了,但注意到我们还有 base case 要处理呀:
// dp 数组全部初始化为 0
int[][] dp = new int[n][n];
// base case
for (int i = 0; i < n; i++) {
dp[i][i] = 1;
}如何把 base case 也打成一维呢?很简单,记住空间压缩就是投影,我们把 base case 投影到一维看看:
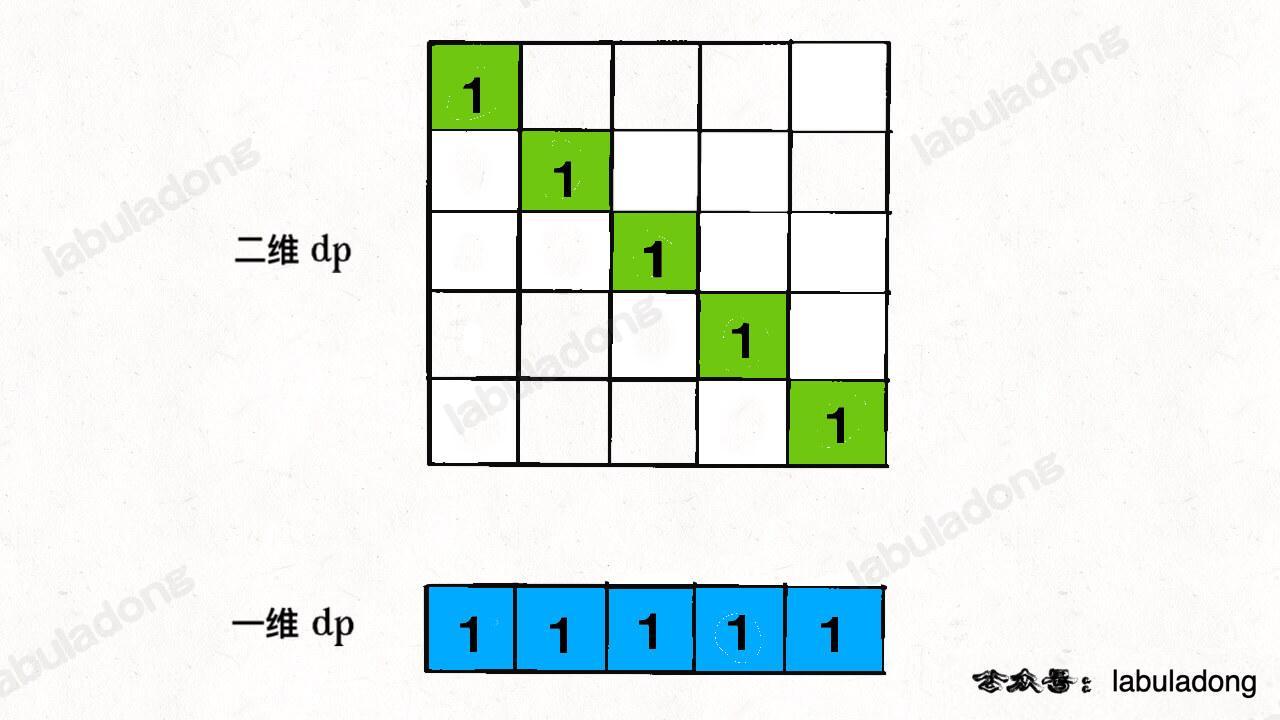
二维 dp 数组中的 base case 全都落入了一维 dp 数组,不存在冲突和覆盖,所以说我们直接这样写代码就行了:
// base case:一维 dp 数组全部初始化为 1
int[] dp = new int[n];
Arrays.fill(dp, 1);至此,我们把 base case 和状态转移方程都进行了降维,实际上已经写出完整代码了:
int longestPalindromeSubseq(String s) {
int n = s.length();
// base case:一维 dp 数组全部初始化为 1
int[] dp = new int[n];
Arrays.fill(dp, 1);
for (int i = n - 2; i >= 0; i--) {
int pre = 0;
for (int j = i + 1; j < n; j++) {
int temp = dp[j];
// 状态转移方程
if (s.charAt(i) == s.charAt(j))
dp[j] = pre + 2;
else
dp[j] = Math.max(dp[j], dp[j - 1]);
pre = temp;
}
}
return dp[n - 1];
}本文就结束了,不过空间压缩技巧再牛逼,也是基于常规动态规划思路之上的。
你也看到了,使用空间压缩技巧对二维 dp 数组进行降维打击之后,解法代码的可读性变得非常差了,如果直接看这种解法,任何人都是一脸懵逼的。算法的优化就是这么一个过程,先写出可读性很好的暴力递归算法,然后尝试运用动态规划技巧优化重叠子问题,最后尝试用空间压缩技巧优化空间复杂度。
也就是说,你最起码能够熟练运用我们前文 动态规划框架套路详解 的套路找出状态转移方程,写出一个正确的动态规划解法,然后才有可能观察状态转移的情况,分析是否可能使用空间压缩技巧来优化。
希望读者能够稳扎稳打,层层递进,对于这种比较极限的优化,不做也罢。毕竟套路存于心,走遍天下都不怕!
引用本文的文章
_____________
《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复「全家桶」可下载配套 PDF 和刷题全家桶:
